|
|
|
|
|
|
|
|
Previous Section | Next Section
3.1 How Push is Really Automated Pull
The Web currently requires the user to poll sites for new or updated information. This manual polling and downloading process is referred to as "pull" technology. From a business point of view, this process provides little information about a user, and offers little control over what information is acquired. It is the user who has to keep track of the location of the information sites, and the user has to remember to continuously search for informational changes--a very time consuming process.
The push model alleviates much of this tedium. Interestingly enough, from a technical point of view, most push applications are still "pull" and just appear to be "push" to the user. A more accurate description of this process is automated pull. Most push applications require a subscription and an information request profile from the user before they can begin filtering information. They also require the client to poll the server when it is able to accept information. The software initiates the "pull" according to a user-defined schedule (once a day, every three hours, etc.), and the server responds with the information to match the request profile.
There are a couple of true push technology applications--one being Wayfarer's Incisa* product. When the Incisa client is started, it opens a connection to the Incisa server and it stays open until the client is stopped. Another true push technology is AirMedia Live* from Air Media. This technology uses the broadcast radio spectrum to transmit to their client applications. The client application is a combination of a radio receiver and a software application. The radio receiver is always receiving information from the server/transmitter.
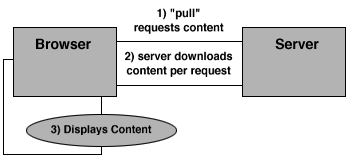
Figure 4: Current Environment--Pull
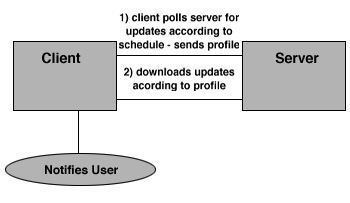
Figure 5: Push as Automated Pull
So if push applications are not really push what is so different about them? The difference is the automation of the process for both the publisher and the subscriber.
3.2 Information Delivery Models
There are at least three (3) information delivery models by which push applications can be categorized. These models differ in the costs incurred for purchase and uptime, the ease of use, the ease of integration into a publisher's existing information delivery structure, the customization capabilities, the branding adherence, and in other areas that a publisher should examine with regard to need.
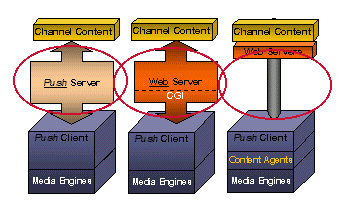
Figure 6: Information Delivery Models
The most common delivery model is the PUSH SERVER model. This is a turnkey solution that provides a client, server, and development tools. Costs associated with the server may include the number of connections and/or the number of packets sent. Branding may or may not be an issue. A proprietary client is supplied. These applications may use a proprietary protocol.
3.2.2 Web Server Extension - CGI
A closely related model is the WEB SERVER EXTENSION model. In this model, the push vendor does not buy a server, so the costs are associated with the number of extensions sold. Feedback and demographic information can be directed to an external server, so that information can be retained by the push vendor (transfer costs may need to be negotiated separately). Installation should be less extensive since no true server is involved. No proprietary client is required; these run within the user's regularly installed browser.
The final model does not need to have a server at all, except to update client software and retain user demographics. This model uses a "client agent" to retrieve the information from sites. Each agent is designed to provide different search results. This model can allow for an anonymous relationship between the vendor and the subscriber. Costs are associated with the agent customization. The user is responsible for deployment, and controls the search type extensibility.
Back to Cookbooks | Back to Top
Previous Section | Next Section
* Other brands and names are the property of their respective owners